Sjov med Excel med Kasper fra Proximo
Bliv bedre til Excel
Sjov med Excel Med Kasper fra Proximo
Excel er – og har altid været – min “skarpe kniv” til både små og store datamængder. Jeg brugte Excel 23 år, da jeg var på arbejdsmarkedet, og nu, hvor jeg er udenfor arbejdsmarkedet, forsøger jeg altid at optimere alt muligt, dels fordi det er sjovt, dels fordi det sparer en masse tid. Og det er lærerigt. Herudover vil jeg gerne holde min hjerne i gang, ved at udskyde aldringprocesserne og påvirke neuroplasticiteten. Hjernen skal stilles opgaver!
Jeg bruger blandt andet Excel til:
- at styre oprydningen slægtsdata i Legacy vha. en kombination af Excel og tags i Legacy.
- Eksempelvis er det smart at kunne trække en liste over, hvilke personer i Legacy, jeg endnu ikke har gennemgået.
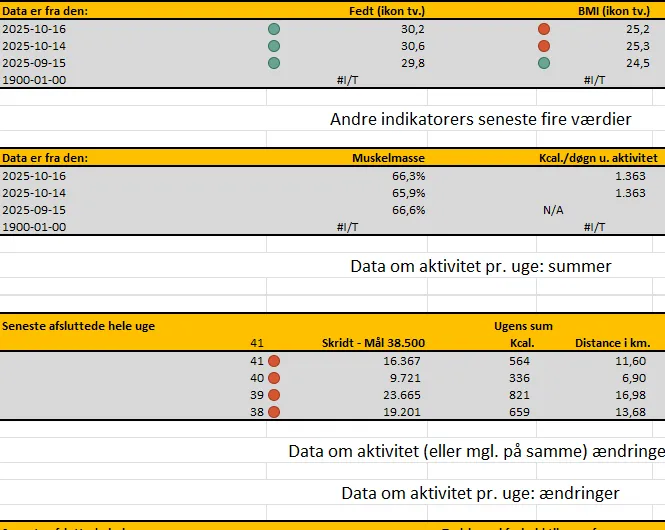
- et “Sundhedsdata“-ark holder øje med fx vægt, aktivitet, blodtryk, puls osv.
- Det sjove var at lave rapporten, som kan printes ud og drøftes med Distriktspsykiatrien.
- at styre budgettet, der fx beregner, hvad saldoen på budgetkontoen skal være den 1. januar, for at kontoen kan “passe sig selv” hele året, fordi jeg ved, at der altid vil være nok også til de dyre måneder.
- Jeg behøver i årets løb overhovedet ikke kigge på kontoen.
- Alligevel kan jeg ikke lade være at kigge på regnearket og sammenholde det med saldoen i netbank for at se, om det nu også passer – men det gør det!
- et par makroer, som ChatGPT har skrevet, hjælper med hurtigt at lave den månedlige budgetopfølgning.
- ved hjælp af en kombination af forespørgsler på mit webhotel og et Excelark holder jeg øje med, hvor meget tid jeg i gennemsnit bruger på artikler her på hjemmesiden og hvor meget tid jeg gennemsnitligt bruger på en artikel.
- Det er ingen videnskab, for af og til glemmer jeg at indsætte starttidspunktet i Excel, og andre gange glemmer jeg at indtaste sluttidspunktet. Men det er bedre end ingenting, og rammer nok gennemsnitligt godt nok til husholdningsbrug.
- År til dato har jeg formentlig brugt ca. 274 timer på 170 artikler. Det giver et gennemsnit pr. artikel på 1:36.
- Osv.
Egentlig synes jeg derfor, jeg er rimeligt god til Excel, men da jeg også elsker læreprocesser, besluttede jeg at købe et medlemskab hos Proximo. Det har jeg haft før, men det var i en periode (2020), hvor jeg ikke havde det ret godt, og så går det ikke godt med indlæringen. De kognitive funktioner er simpelthen nedsatte. Kognition betyder nærmest “tænkning”.
Billedet herunder er et udsnit fra rapporten “Sundhedsdata”. Som det ses har jeg en periode motioneret for lidt. Da jeg motiveres af data, er jeg begyndt at rette op på det! Jeg vil jo gerne have grønne prikker alle steder.

Det der er næsten nyt
Jeg var eksempelvis ikke blevet ret god til funktionerne LOPSLAG, HVIS eller SUM.HVIS og SUM.HVISER nåede jeg vist aldrig til.
Og så vil jeg så gerne kunne skrive nogle simple makroer. Hidtil har ChatGPT gjort det for mig, hvilket også har været både godt og fint, men jeg vil gerne lære bare lidt af det selv, da samarbejdet med ChatGPT af og til bliver for bøvlet, og den ødelægger de data, man allerede har. Det er jo bare en robot, selvom den er fantastisk.
Samarbejder du med ChatGPT, skal du i hvert fald sikre dig, at du har en backup af filen, du uploader.
Det er sindssyg sjovt
Jeg begyndte på kurset i går, og det er allerede gået op for mig, hvor meget tid jeg har spildt i mit liv ved eksempelvis ikke at mestre LOPSLAG, HVIS og SUM.HVIS.
Hvert delemne i et kursus indledes med en video, hvor Kasper fra Proximo forklarer Excels funktion, og hvad man skal være opmærksom på, og han gør det virkelig godt.
Han har udviklet kurserne meget, siden jeg senest havde et abonnement.
Et eksempel er SUM.HVIS, der kan se sådan ud: =SUM.HVIS(Data!K:K;1;Data!I:I), som han forklarer nogenlunde sådan:
- Hvor skal Excel lede efter data? Det er hele kolonne K i arket Data.
- Hvad er kriteriet? Det er de rækker, hvor der står et 1-tal.
- Hvor finder Excel de data (tal), der skal lægges sammen, når den først har fundet rækkerne med et 1-tal? Det er kolonne I.
Det er jo i virkeligheden ganske enkelt, når man altså først har lært det.

Jeg har gennemgået to eller tre af kurserne, og det er utrolig sjovt, hvis man er data-nørd. Hvis du også er data-nørd – eller bare gerne vil blive bedre til Excel – vil jeg varmt anbefale Proximo.

Har du kommentarer til artiklen?
Så er jeg glad for at modtage dem i relation til artiklen, dvs. i artiklens kommentarfelt herunder, ikke på facebook og ikke via Messenger. Det skyldes, at kommentarer og artiklen jo ellers dekobles, og så er din kommentar ikke noget værd i fremtiden. Det er ærgerligt for os begge. Jeg svarer dig også relation til artiklen til morgenkaffen, kl. 13:00, kl. 18:00 og ved sengetid.
Hvis du ikke tidligere har kommenteret en af mine artikler her på siden, skal din kommentar først godkendes (spamhensyn). Min responstid er under normale omstændigheder kort. Jeg svarer til morgenkaffen, kl. 13:00, kl. 18:00 og ved sengetid. Herefter vil du stryge lige igennem.