Jeg har blokeret for SMS’er

Jeg bestemmer, hvor beskederne kommer
Jeg har blokeret for SMS’er
Jeg har bedt YouSee spærre for alle SMS-beskeder på mit abonnement. Ikke fordi jeg hader teknologi, men fordi jeg foretrækker orden og struktur. Når beskeder ligger spredt på SMS, Messenger, Facebook og mail, bliver det sværere at finde det, jeg skal bruge. Jeg vil hellere samle informationerne få steder og bruge gode søgeværktøjer, når jeg mangler noget.
Nu har jeg bedt YouSee spærre for alle SMS’er – ikke kun de indholdstakserede.
Jeg havde haft gang i min ven ChatGPT, inden jeg ringede op, men robotten kom til kort. Den svarede dog, at jeg skulle sige følgende til medarbejderen hos YouSee:
Kan I lægge en netværksspærring på mit abonnement, så jeg ikke kan modtage SMS-beskeder?
Medarbejderen lød noget overrasket og spurgte, hvorfor jeg ville spærre for SMS.
Mit svar var simpelt: “Jeg får alligevel aldrig noget at vide, jeg ikke vidste i forvejen”.
Jeg ved da godt, at jeg skal til frisør, tandlæge osv. Det står jo i min kalender. Og jeg har ikke brug for, at hverken Andel Energi eller YouSee sender mig både en SMS og en email om, at min regning er blevet betalt. Det vidste jeg også godt i forvejen, og jeg forventede det ligefrem, eftersom regningerne er tilmeldt Betalingsservice.
- Jeg kunne aldrig selv drømmer om at sende en SMS.
- Jeg har bare bøvlet med at slette dem.
Viser det sig, at der er uoverstigelige problemer med ikke at kunne modtage SMS’er, må jeg jo ophæve spærringen igen.
De mange forskellige platforme
Jeg har ganske enkelt vanskeligt ved at overskue de mange forskellige platforme, hvor jeg i dag kan modtage meddelelser om et eller andet. Jeg holder indbakken (mail) ren og overskuelig, så der kan jeg finde det, jeg behøver. Men det er umuligt at huske alt det andet. Hvor var det nu, jeg modtog en meddelelse? Var det på SMS, Messenger, Facebook eller …?
Det minder mig om mennesker, der fx af og til gemmer et eller andet sted i skyen og nogle gange på PC’en. Hvor skal de så lede?
Struktur på PC’en
Jeg gemmer vigtige dokumenter på min PC, hvorfra der dagligt tages automatisk backup efter 3-2-1-princippet (lyt evt. til denne episode i Danske Slægtsforskeres podcast).
3-2-1-princippet stammer fra finansverdenen og drejer sig om risikospredning. “Man skal ikke lægge alle sine æg i samme kurv” betyder oprindeligt, at man ikke skal investere alle sin penge i en bestemt type aktier, fx ikke alle sparepengene i Novo-aktier. Man skal købe aktierne hos mange forskellige firmaer..
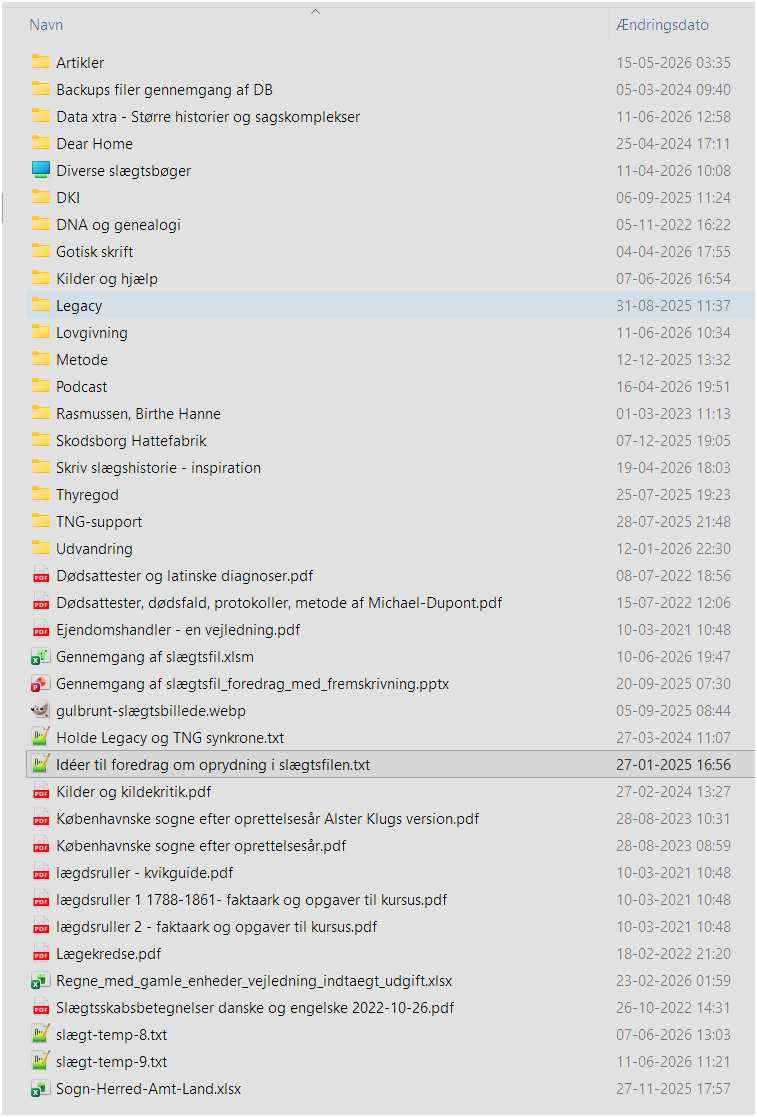
Min PC er ryddelig og med en struktur, jeg nemt kan finde rundt i. Allernederst i denne artikel har du et billede, der stammer fra Dokumenter > Genealogi. Inde i mapperne er der yderligere mapper, så jeg på under 30 sekunder nemt finder det, jeg skal bruge.
Søgemaskiner på PC’en
Kan jeg alligevel ikke finde et eller andet, bruger jeg programmet “Everything”. Programmet er gratis og genialt. Det søger med lynets hast på filnavne og den slags.
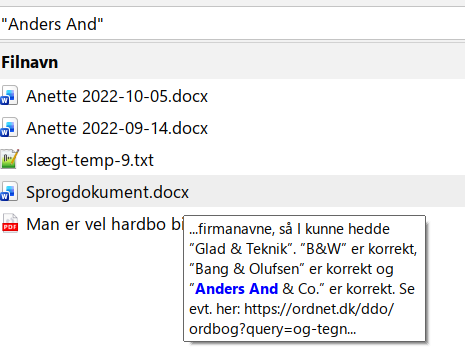 En anden fantastisk gratis søgemaskine på PC’en er programmet “Anytxt Searcher”, der nemt søger på ord inde i tekster.
En anden fantastisk gratis søgemaskine på PC’en er programmet “Anytxt Searcher”, der nemt søger på ord inde i tekster.
Man skal selvfølgelige lige give programmet til at indeksere måske tusindvis af filer og måske millioner af ord. Det går lynhurtigt.
Derefter er det helt fantastisk. Her har jeg eksempelvis søgt på frasen “Anders And”, som søgemaskinen på få sekunder finder i fem dokumenter.
- Når jeg holder musen over et dokument, får jeg i venstre kolonne at vide, hvad der helt præcist står inde i dokumentet.
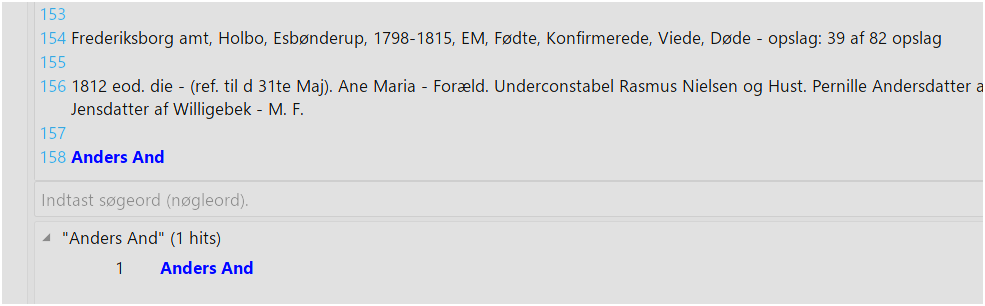
- Det samme gælder højre side, men her får jeg hele konteksten vist. Se billedet herunder, hvor der står “Anders And” i linje 158.
- Endnu genialere 🙂 end Everything, fordi jeg ikke behøver åbne dokumentet.
Har du kommentarer til artiklen?
Så er jeg glad for at modtage dem i relation til artiklen, dvs. i artiklens kommentarfelt herunder, ikke på Facebook og ikke via Messenger – og ikke via SMS. Det skyldes, at kommentarer og artiklen jo ellers dekobles, og så er din kommentar ikke noget værd i fremtiden. Det er ærgerligt for os begge. Jeg svarer dig også relation til artiklen til morgenkaffen, kl. 13:00, kl. 18:00 og ved sengetid.
Hvis du ikke tidligere har kommenteret en af mine artikler her på siden, skal din kommentar først godkendes (spamhensyn). Min responstid er under normale omstændigheder kort. Jeg svarer til morgenkaffen, kl. 13:00, kl. 18:00 og ved sengetid. Herefter vil du stryge lige igennem.


 En tidsrejse
En tidsrejse

 FastStone Image Viewer
FastStone Image Viewer